Automatic Movie Content Analysis
The MoCA Project 
The MoCA Project
Navigation

MoCA Project: Object Recognition
We present an approach which classifies a segmented video object by means of the contours of its appearances in successive video frames. The classification is performed by matching curvature features of the video object contour to a database containing preprocessed views of prototypical objects.
Object recognition can be performed on different levels of abstraction. For instance, an object might be classifiable as "cat"(object class), as "Siamese Cat"(subordinate level) or as "my neighbour's cat"(individual object). We concentrate on the object class level, i. e. video objects are assigned to the class they belong to.
For each two-dimensional appearance of an object in a video frame curvature features of its contour are calculated. These features are matched to those of views of prototypical video objects stored in a database. The final classification of the object is achieved by integrating the matching results for successive frames. This adds reliability to our approach, since unrecognizable single views are insignificant with respect to the whole sequence.
The calculation of the contour description relies on the curvature scale space method. We extended this technique for the processing of video sequences and enhanced it by extracting additional information from the CSS image.
Our system for object classification consists of two major parts:
- a database containing representations of prototypical video objects and
- an algorithm for matching extracted video objects with the database.
In the following we provide details for the chosen object representation and the matching algorithm.
Object Representation
In general, there are two possibilities for generating object related information. First, one could extract features from a 3D object model, and second, it is feasible to use two-dimensional views of an object as basis. In cognitive psychology a number of theories have been developed with regard to object representation in the human brain. Although a general theory is not available, psychophysical evidence indicates that humans encode three-dimensional objects as multiple viewpoint-specific representations that are largely two-dimensional.
We follow this theory and store for each object class a number of different two-dimensional views (object views). From the views that can be generated from a real-world object we prefer so called canonical views. Canonical views are views that allow humans for easier object recognition. For a car, one possible canonical view is a slightly elevated view of the frontal and side parts of the object. A view of the bottom of a car is in general not considered canonical. The following image shows, on the left, a canonical view of a tricycle. On the right side, a non-canonical view is shown.
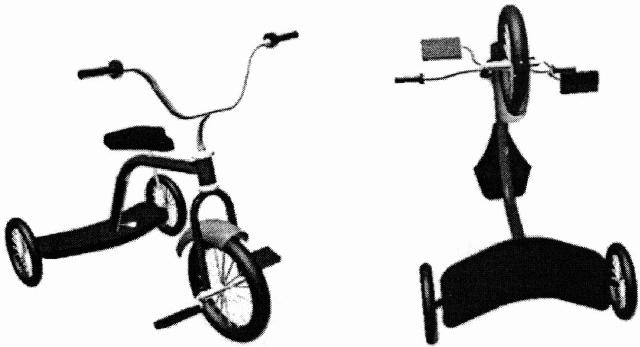
For each object view only a few parameters are stored in the database. These parameters are extracted from the shape of the object view via the Curvature Scale Space (CSS) method. Although different sources of information are available to characterize a two-dimensional view (e. g. shape, colour, texture, motion or relative location of the object), most common objects can be identified by their contours only. The CSS method provides a robust and tolerant way of describing a contour with only a few parameters.
The CSS technique scans the closed contour of an object view for zero crossings of the curvature. This is performed several times as the contour is smoothed by a Gaussian kernel. The smooting of a contour of a giraffe is displayed in the following image:
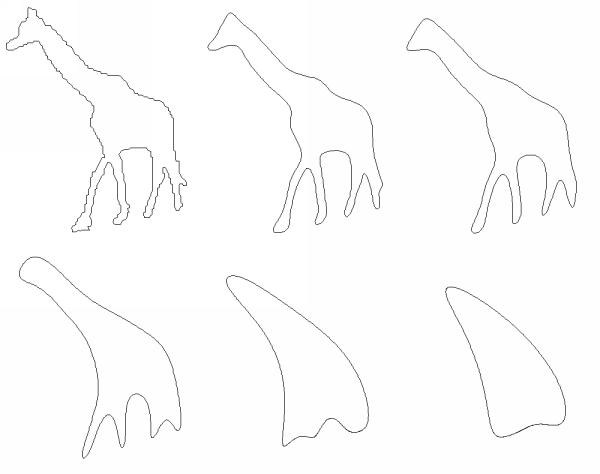
While zero crossings extracted from a strongly smoothed contour give only a rough outline of the object view in question, zero crossing positions gained from earlier iterations provide more details. From the positions of the zero crossings at different scales a so called CSS image is constructed. The following CSS image shows the zero crossings with respect to their position on the contour and the width of the Gaussian kernel.
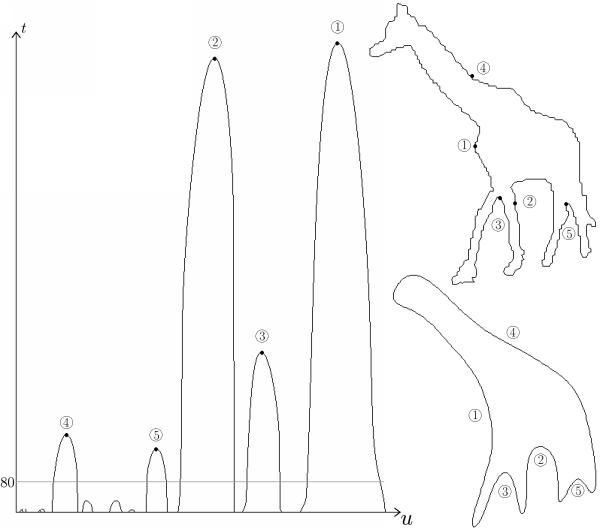
The significant maxima from this image are extracted and stored in the database. Consequently, each object view is represented by a list of tuples - consisting of the position (on the contour) and the value of a CSS maximum (Gaussian kernel width) - within the database.
Object Matching
Calculating the CSS images for a video object yields a list of tuples for each frame. These lists of tuples are matched to each list of tuples of the prototypes in the database. The results of the per frame matching are later accumulated.
For matching a CSS image to another, the CSS maxima are compared. To compensate for possible mirroring or rotation of the image, preprocessing is necessary. Each matching procedure is done for the original object contained in a video frame and for its mirrored version. Only mirroring on the y-axis is necessary, since mirroring on the x-axis can be simulated by a combination of mirroring on the y-axis and rotation.
Mirroring of the object view on the y-axis is equivalent to mirroring of the CSS image. A rotation of the original object view corresponds to shifting the CSS image along the x-axis. A list of potentially interesting shift offsets is build in a first step to minimize the number of comparisons. For each shift offset, the distance between the CSS image of the object view and the CSS image of the prototype in the database is calculated.
The list of tuples representing the CSS image of the object view are sorted according to the value of the CSS maxima. Beginning with the largest CSS maximum, each one is matched to a maximum of the prototype which was not visited. The distance between the CSS image of the object view and the CSS image of the prototype is the summarized Euclidean distance between the heights and positions of the maxima.
The position of a CSS maximum is an integer from a fixed interval. The value of the CSS maximum is the size of the Gaussian mask and can be arbitrarily large. Therefore, the position is often not adequately represented if only the Euclidean distance is calculated. By only considering maxima which are in the closer neighbourhood of a CSS maximum, this shortcoming is compensated. If no match for a maximum is found, the height of that maximum and an additional penalty is added to the total distance.
The described procedure yields a distance between an object view and a prototype in the database. After calculating this distance for each prototype, the best one can be determined. Based on the result, the object view can be grouped into an object class. For each object class the number of matched images from the sequence and the cumulated distances are stored in an array.
The final match is determined based on the object class information array. The object class with the most matches is considered to be the object class of the video object. A confidence value is provided by relating the cumulated distance values of the object class to the sum of all cumulated distances. The closer this number is to 100, the better the match.
Results
Our test database contains five different object classes. For each object class, we collected images from a clip art library. The clip arts are typical representatives of their object class and are shown in easily recognizable perspectives. Table 1 shows the number of prototypes for each object class.
| Object class | # of prototypes |
| Animals | 19 |
| Cars | 44 |
| Misc | 20 |
| People | 96 |
| Birds | 19 |
Table 1: Number of prototypes per object class
Several short real world video sequences were tested. Some of the sequences were automatically segmented using different methods. The results of these sequences are shown in table 2. Good results (+) indicate that a sufficient confidence value was reached.
| Sequence name | # of frames | detected class | ok |
| akiyo | 25 | People | + |
| changick | 38 | People | + |
| hall and monitor | 81 | Cars | - |
Table 2: Automatically segmented sequences and results
Other sequences were segmented manually. The results for these sequences are shown in table 3.
| Sequence name | # of frames | detected class | ok |
| Car1 | 19 |
Cars | + |
| Car2 | 51 |
Cars | + |
| Car3 | 63 |
Cars | + |
| Human1 | 164 |
People | + |
| Human2 | 28 |
People | + |
| Human3 | 12 |
People | + |
| Bird1 | 66 |
Cars |
- |
| Bird2 | 13 |
People | - |
Table 3: Manually segmented sequences and the results
The following animations show the "Human3"sequence:


The top six result images are shown in the next image:

In the sequences entitled "Bird1", a dove walks away from the camera. Rear views of birds are not in the database, therefore recognition was not possible.
In "Bird2", a dove walks and lifts off the ground. During this scene, the dove as video object is heavily deformed and even for a human being it is not recognizable if no further context than the contour is given.