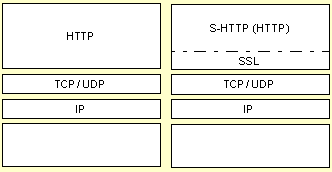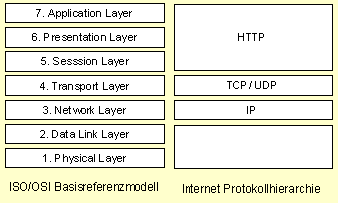
Im Falle des WWW wird HTTP standardmäßig über TCP Port 80 abgewickelt. Nach Definition, RFC (Request for Comments) 2068 ist aber auch jede beliebige, gesicherte Verbindung erlaubt, so daß sich das HTTP auch für andere Anwendungen neben dem World Wide Web einsetzen läßt.
Der grundsätzliche Ablauf einer HTTP Übertragung stellt sich wie folgt dar:

"http:" "//" host [ ":" port ] [abs_path]
host |
Ein zulässiger Internet Rechner-Domain-Name oder eine IP-Nummer. |
port |
Der TCP-Port auf welchem der "host" HTTP-Anfragen entgegennimmt. Fehlt die Angabe wird defaultmäßig Port 80 verwendet. |
abs_path |
Der Pfad zu dem gewünschten Dokument im Verzeichnissystem des Servers. Die Angabe ist ebenfalls optional. Standardmäßig wird in der Regel die Homepage der zu "host" gehörigen Website (des Betreibers) geladen |
http://www.uni-karlsruhe.de
entspricht
http://www.uni-karlsruhe.de:80/Uni/index.html
| Client:
GET / HTTP/1.0 Accept: */* Accept: application/html Accept: text/plain Accept: text/html Accept: www/mime Accept-Language: en; q=1 Accept-Language: *; q=0.1 User-Agent: Lynx/2-4-2 libwww/2.14 <Leerzeile> |
| Server:
HTTP/1.1 200 OK Date: Mon, 27 Oct 1997 11:57:03 GMT Server: Apache/1.2.1 PHP/FI-2.0b12 Last-Modified: Wed, 13 Aug 1997 07:30:38 GMT ETag: "64861-57c-33f1629e" Content-Length: 1404 Connection: close Content-Type: text/html <!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML//EN">
<HTML>
|
Hier eine kurze Beschreibung einiger Elemente:
| GET | Veranlaßt die Übertragung des gesamten Dokumentes. Alternativ läßt sich z.B. mit HEAD nur der Kopf der HTML-Datei übertragen (z.B. zum Lesen des Titels und der Meta-Informationen von Suchmaschinen) |
| Accept: www/mime | Zeigt dem Server den vom Client gewünschten Datentyp an. Wie hier sind mehrere solcher Einträge für verschiedene Typen zulässig. MIME steht für Multipurpose Internet Mail Extensions. (Näheres zu MIME siehe Thema 2) |
| HTTP/1.1 200 OK | Die Anfrage ist vom Server verstanden worden; der Server ist HTTP Version 1.1 fähig (hier jedoch vom Client nicht unterstützt) |
| Server | Die verwendete Serversoftware. Durch Auswertung dieses Response-Eintrages läßt sich die oben beschriebene Grafik vollautomatisch erstellen |
| Connection: close | Die Verbindung wird nach Übertragung dieser einen Datei geschlossen. (Keine Persistent Connection) |
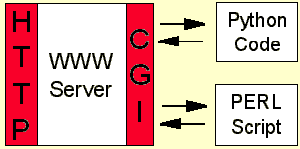
Die Anwendung liegt insbesondere in der Bereitstellung von dynamisch erzeugten Webseiten. Bei Suchmaschinen z.B. kann die dem Client zu übertragende WWW-Seite ja erst nach der Eingabe der gesuchten Schlagworte erstellt werden. Dies geschieht dann, indem das CGI-Programm als Rückgabewerte den HTML-Code dieser Seite übergibt.
Am Beispiel Suchmaschine erkennt man auch, daß ein enger Zusammenhang
zwischen dem Einsatz von CGIScripten und Formularen im WWW besteht. In
Formularen stehen zwei Methoden zur Übergabe von Daten durch den HTTP-Server
an das CGI-Programm zu Verfügung:
http://www.irgendwo.de/cgi-bin/beispiel.cgi?vorname=paul&nachname=meier
Das CGI-Script muß in diesem Falle die Umgebungsvariable QUERY_STRING
des Servers auslesen.
Außer der Umgebungsvariablen QUERY_STRING existieren noch zahlreiche andere, z.B. REMOTE_HOST, SERVER_NAME, CONTENT_TYPE, CONTENT_LENGTH. Mit deren Hilfe lassen sich zum Beispiel einfache Zugangsbeschränkungen realisieren, indem nur bestimmten Rechnern (REMOTE_HOST) der Zugriff gestattet wird.
Hier ein in Python
programmiertes, einfaches
Beispiel zur Verwendung von CGI-Scripten und Formularen (POST-Methode)
sowie Nutzung von Umgebungsvariablen.
Derartige Aufgaben lassen sich mit folgenden Lösungsmöglichkeiten
bewältigen:
An diesem einfachen
Addierer läßt sich dieser Mechanismus leicht ausprobieren.
Sobald nun der Benutzer den selben URL das nächste mal abruft, schickt der Browser die gespeicherten Informationen selbständig an den an den Server zurück. Dieser Datenaustausch geschieht in der Regel über spezielle HTTP-Request/Response - Felder. Aber auch mit Hilfe von JavaScript lassen sich Cookies schreiben und lesen.
Entgegen der weitverbreiteten Meinung besteht wenig Gefahr für den unerlaubten Zugriff auf private Daten von Außen. Cookies werden im Normalfall nur an denjenigen Server zurückgeschickt, von welchem sie ursprünglich stammen. Außerdem wird das Lesen und Schreiben auf die lokale Festplatte des Anwenders alleine vom Browser durchgeführt und ist somit vom WWW-Server nicht kontrollierbar.
Cookies sind allerdings nicht unumstritten, da sie die Erstellung von personenbezogenen Nutzungsprofilen begünstigen. Dies geschieht z.B. dadurch, das entsprechende Organisationen Werbung auf möglichst vielen fremden WWW-Seiten plazieren. Da diese Werbebanner nicht statisch z.B. als Grafikdatei an die Eigentümer der Sites vergeben, sondern jedesmal von einem zentralen Server eingespielt werden, läßt sich auch somit jedesmal ein Cookie setzen und wieder lesen. Auf diese Weise kann man die Spur eines bestimmten Websurfers über weite Strecken im WWW verfolgen.
Weiterführend hier die genaue (vorläufige) Spezifikation
über HTTP Cookies der Firma Netscape.
Zum Ausgleich dieser Unzulänglichkeiten stehen derzeit im wesentlichen
zwei Methoden zur Verfügung:
Beim SSL wird zunächst durch ein asymmetrisches Verschlüsselungsverfahrens (RSA) ein Schlüssel für ein symmetrisches Verfahren (DES) ausgetauscht. Mit letzerem werden schließlich die zu übertragenden Daten verschlüsselt. Diese Kombination ist sinnvoll, da asymmetrische Verfahren zwar keinen gesicherten Übertragungskanal für den Schlüssel benötigen, sich dafür aber wegen des hohen Rechenaufwandes nur für die Verschlüsselung kurzer Nachrichten wie z.B. eines Schlüssels für ein symmetrisches Verfahren eignen.
Weiterführende Information en hierzu im Rahmen von Thema
7 - Sicherheit der Datenübertragung im Internet.